Fork / Join-biblioteket, der blev introduceret i Java 7, udvider den eksisterende Java-samtidighedspakke med understøttelse af hardware-parallelisme, et nøglefunktion i multicore-systemer. I dette Java-tip demonstrerer Madalin Ilie ydeevneeffekten af at udskifte Java 6 ExecutorService klasse med Java 7'er ForkJoinPool i en webcrawler-applikation.
Webcrawlere, også kendt som webspiders, er nøglen til søgemaskiners succes. Disse programmer scanner vedvarende internettet og samler millioner af sider med data og sender dem tilbage til søgemaskindatabaser. Dataene indekseres derefter og behandles algoritmisk, hvilket resulterer i hurtigere og mere nøjagtige søgeresultater. Mens de mest berømte bruges til søgeoptimering, kan webcrawlere også bruges til automatiserede opgaver såsom linkvalidering eller at finde og returnere specifikke data (såsom e-mail-adresser) i en samling websider.
Arkitektonisk set er de fleste webcrawlere højtydende multitrådede programmer, omend med relativt enkle funktioner og krav. Opbygning af en webcrawler er derfor en interessant måde at øve såvel som at sammenligne, flertrådede eller samtidige programmeringsteknikker.
Tilbagevenden til Java Tips!
Java Tips er korte kodedrevne artikler, der inviterer JavaWorld-læsere til at dele deres programmeringsevner og opdagelser. Fortæl os, hvis du har et tip til at dele med JavaWorld-samfundet. Tjek også Java Tips Archive for flere programmeringstip fra dine kammerater.
I denne artikel gennemgår jeg to tilgange til at skrive en webcrawler: den ene bruger Java 6 ExecutorService og den anden Java 7s ForkJoinPool. For at følge eksemplerne skal du (med denne skrivning) have Java 7-opdatering 2 installeret i dit udviklingsmiljø såvel som tredjepartsbiblioteket HtmlParser.
To tilgange til Java-samtidighed
Det ExecutorService klasse er en del af java.util.concurrent revolution introduceret i Java 5 (og selvfølgelig en del af Java 6), hvilket forenklede trådhåndtering på Java-platformen. ExecutorService er en eksekutor, der giver metoder til at styre fremskridtssporing og afslutning af asynkrone opgaver. Før introduktionen af java.util.concurrent, Java-udviklere stolede på tredjepartsbiblioteker eller skrev deres egne klasser for at administrere samtidighed i deres programmer.
Fork / Join, introduceret i Java 7, er ikke beregnet til at erstatte eller konkurrere med de eksisterende samtidighedsprogrammer; i stedet opdateres og fuldføres dem. Fork / Join imødekommer behovet for divide-and-conquer, eller rekursiv opgavebehandling i Java-programmer (se Ressourcer).
Fork / Join's logik er meget enkel: (1) adskil (fork) hver store opgave i mindre opgaver; (2) behandle hver opgave i en separat tråd (om nødvendigt adskille dem i endnu mindre opgaver); (3) slutte sig til resultaterne.
De to webcrawlerimplementeringer, der følger, er enkle programmer, der viser funktionerne og funktionaliteten i Java 6 ExecutorService og Java 7 ForkJoinPool.
Opbygning og benchmarking af webcrawleren
Vores webcrawlers opgave er at finde og følge links. Dens formål kan være linkvalidering, eller det kan være at indsamle data. (Du kan f.eks. Instruere programmet om at søge på nettet efter billeder af Angelina Jolie eller Brad Pitt.)
Applikationsarkitekturen består af følgende:
- En grænseflade, der udsætter grundlæggende operationer for at interagere med links; dvs. få antallet af besøgte links, tilføj nye links, der skal besøges i kø, markér et link som besøgt
- En implementering af denne grænseflade, der også vil være startpunktet for applikationen
- En tråd / rekursiv handling, der holder forretningslogikken for at kontrollere, om et link allerede er besøgt. Hvis ikke, samler det alle links på den tilsvarende side, opretter en ny tråd / rekursiv opgave og sender den til
ExecutorServiceellerForkJoinPool - En
ExecutorServiceellerForkJoinPooltil at håndtere ventende opgaver
Bemærk, at et link betragtes som "besøgt", efter at alle links på den tilsvarende side er returneret.
Ud over at sammenligne let udvikling ved hjælp af samtidige værktøjer, der er tilgængelige i Java 6 og Java 7, sammenligner vi applikationsydelse baseret på to benchmarks:
- Søg dækning: Måler den tid, det tager at besøge 1.500 tydelig links
- Behandlingskraft: Måler den tid i sekunder, der kræves for at besøge 3.000 ikke-særskilt links; det er som at måle, hvor mange kilobit i sekundet din internetforbindelse behandler.
Mens de er relativt enkle, vil disse benchmarks give mindst et lille vindue til ydeevnen af Java-samtidighed i Java 6 versus Java 7 for visse applikationskrav.
En Java 6-webcrawler bygget med ExecutorService
Til implementering af Java 6-webcrawler bruger vi en fast trådpulje på 64 tråde, som vi opretter ved at kalde Executors.newFixedThreadPool (int) fabriksmetode. Liste 1 viser implementeringen af hovedklassen.
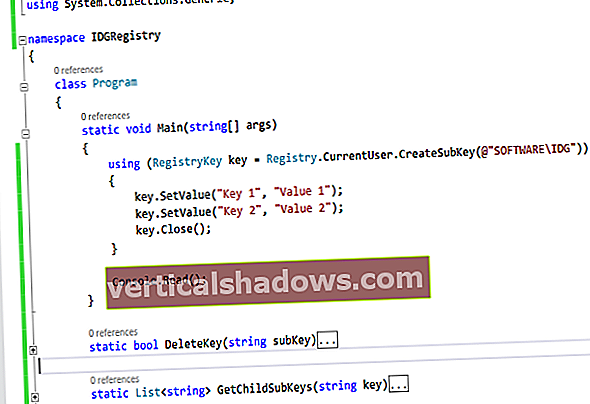
Fortegnelse 1. Konstruktion af en WebCrawler
pakke insidecoding.webcrawler; import java.util.Collection; import java.util.Collections; importer java.util.concurrent.ExecutorService; importere java.util.concurrent.Executors; import af insidecoding.webcrawler.net.LinkFinder; importere java.util.HashSet; / ** * * @forfatter Madalin Ilie * / offentlig klasse WebCrawler6 implementerer LinkHandler {privat endelig samling besøgtLinks = Collections.synchronizedSet (nyt HashSet ()); // privat endelig samling Besøgte links = Collections.synchronizedList (ny ArrayList ()); privat String url; privat ExecutorService execService; offentlig WebCrawler6 (streng startURL, int maxThreads) {this.url = startURL; execService = Executors.newFixedThreadPool (maxThreads); } @ Overstyr offentlig ugyldig køLink (strenglink) kaster undtagelse {startNewThread (link); } @ Override public int-størrelse () {return visitedLinks.size (); } @Override public void addVisited (String s) {visitedLinks.add (s); } @ Override offentlig boolsk besøgte (String (er)) {return visitedLinks.contains (s); } privat ugyldig startNewThread (strenglink) kaster undtagelse {execService.execute (ny LinkFinder (link, dette)); } privat ugyldig startCrawling () kaster Undtagelse {startNewThread (this.url); } / ** * @param argumenterer for kommandolinjeargumenterne * / public static void main (String [] args) throw Exception {new WebCrawler ("// www.javaworld.com", 64) .startCrawling (); }} I ovenstående WebCrawler6 konstruktør, opretter vi en trådpulje med fast størrelse på 64 tråde. Vi starter derefter programmet ved at ringe til startCrawling metode, som opretter den første tråd og sender den til ExecutorService.
Dernæst opretter vi en LinkHandler interface, som afslører hjælpemetoder til at interagere med URL'er. Kravene er som følger: (1) marker en URL som besøgt ved hjælp af addVisited () metode; (2) få antallet af de besøgte webadresser gennem størrelse() metode; (3) afgøre, om en URL allerede er besøgt ved hjælp af besøgte () metode; og (4) tilføj en ny URL i køen gennem køLink () metode.
Liste 2. LinkHandler-grænsefladen
pakke insidecoding.webcrawler; / ** * * @forfatter Madalin Ilie * / offentlig grænseflade LinkHandler {/ ** * Placerer linket i køen * @param link * @throws Undtagelse * / ugyldig queueLink (strenglink) kaster Undtagelse; / ** * Returnerer antallet af besøgte links * @return * / int størrelse (); / ** * Kontrollerer, om linket allerede var besøgt * @param link * @return * / boolsk besøgte (String link); / ** * Markerer dette link som besøgt * @param link * / void addVisited (String link); } Nu, når vi gennemsøger sider, skal vi starte resten af trådene, hvilket vi gør via LinkFinder interface, som vist i liste 3. Bemærk linkHandler.queueLink (l) linje.
Liste 3. LinkFinder
pakke insidecoding.webcrawler.net; import java.net.URL; importer org.htmlparser.Parser; import org.htmlparser.filters.NodeClassFilter; importer org.htmlparser.tags.LinkTag; importer org.htmlparser.util.NodeList; importer insidecoding.webcrawler.LinkHandler; / ** * * @forfatter Madalin Ilie * / offentlig klasse LinkFinder implementerer Runnable {private String url; privat LinkHandler linkHandler; / ** * Brugt fot statistik * / privat statisk endelig lang t0 = System.nanoTime (); public LinkFinder (String url, LinkHandler handler) {this.url = url; this.linkHandler = handler; } @ Override public void run () {getSimpleLinks (url); } privat ugyldigt getSimpleLinks (String url) {// hvis ikke allerede besøgt hvis (! linkHandler.visited (url)) {prøv {URL uriLink = ny URL (url); Parser parser = ny Parser (uriLink.openConnection ()); NodeList liste = parser.extractAllNodesThatMatch (ny NodeClassFilter (LinkTag.class)); Liste url = ny ArrayList (); for (int i = 0; i <list.size (); i ++) {LinkTag ekstraheret = (LinkTag) list.elementAt (i); hvis (! extracted.getLink (). er tom () &&! linkHandler.visited (extracted.getLink ())) {urls.add (extracted.getLink ()); }} // vi besøgte denne url linkHandler.addVisited (url); hvis (linkHandler.size () == 1500) {System.out.println ("Tid til at besøge 1500 forskellige links =" + (System.nanoTime () - t0)); } for (String l: urls) {linkHandler.queueLink (l); }} fange (Undtagelse e) {// ignorere alle fejl for nu}}}} Logikken i LinkFinder er simpelt: (1) vi begynder at analysere en URL; (2) efter at vi har samlet alle linkene inden for den tilsvarende side, markerer vi siden som besøgt; og (3) vi sender hvert fundet link til en kø ved at ringe til køLink () metode. Denne metode opretter faktisk en ny tråd og sender den til ExecutorService. Hvis der er "gratis" tråde i puljen, udføres tråden; ellers placeres den i en ventekø. Efter at vi når 1.500 forskellige besøgte links, udskriver vi statistikken, og programmet kører fortsat.
En Java 7-webcrawler med ForkJoinPool
Fork / Join-rammen introduceret i Java 7 er faktisk en implementering af Divide and Conquer-algoritmen (se Ressourcer), hvor en central ForkJoinPool udfører forgrening ForkJoinTasks. I dette eksempel bruger vi en ForkJoinPool "bakket op" af 64 tråde. jeg siger bakkes op fordi ForkJoinTasks er lettere end tråde. I Fork / Join kan et stort antal opgaver være vært for et mindre antal tråde.
Svarende til Java 6-implementeringen starter vi med at instantiere i WebCrawler7 konstruktør a ForkJoinPool objekt understøttet af 64 tråde.
Notering 4. Java 7 LinkHandler-implementering
pakke insidecoding.webcrawler7; import java.util.Collection; import java.util.Collections; import java.util.concurrent.ForkJoinPool; importer insidecoding.webcrawler7.net.LinkFinderAction; importere java.util.HashSet; / ** * * @forfatter Madalin Ilie * / offentlig klasse WebCrawler7 implementerer LinkHandler {privat endelig samling besøgtLinks = Collections.synchronizedSet (nyt HashSet ()); // privat endelig samling Besøgte links = Collections.synchronizedList (ny ArrayList ()); privat String url; privat ForkJoinPool mainPool; offentlig WebCrawler7 (streng startURL, int maxThreads) {this.url = startURL; mainPool = ny ForkJoinPool (maxThreads); } privat ugyldig startCrawling () {mainPool.invoke (ny LinkFinderAction (denne.url, denne)); } @ Override public int-størrelse () {return visitedLinks.size (); } @Override public void addVisited (String s) {visitedLinks.add (s); } @ Override offentlig boolsk besøgte (Streng (er) {retur besøgte Links. Indeholder (r); } / ** * @param argumenterer for kommandolinjeargumenterne * / public static void main (String [] args) kaster undtagelse {new WebCrawler7 ("// www.javaworld.com", 64) .startCrawling (); }} Bemærk, at LinkHandler interface i Listing 4 er næsten den samme som Java 6-implementeringen fra Listing 2. Det mangler kun køLink () metode. De vigtigste metoder at se på er konstruktøren og startCrawling () metode. I konstruktøren opretter vi et nyt ForkJoinPool bakket op af 64 tråde. (Jeg har valgt 64 tråde i stedet for 50 eller et andet rundt nummer, fordi i ForkJoinPool Javadoc siger, at antallet af tråde skal være en styrke på to.) Puljen påkalder en ny LinkFinderAction, som rekursivt påberåber sig yderligere ForkJoinTasks. Liste 5 viser LinkFinderAction klasse: