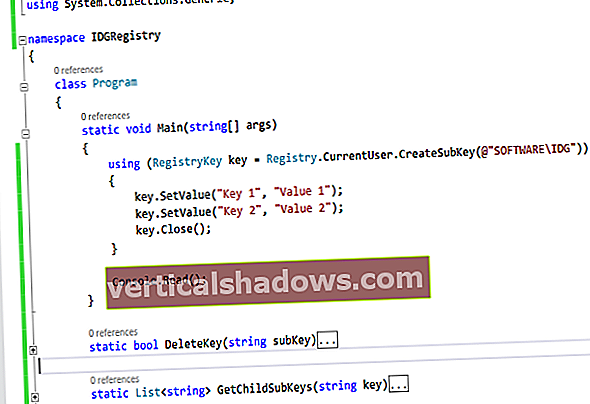
Lexikal analyse og parsing
Når du skriver Java-applikationer, er en af de mere almindelige ting, du skal producere, en parser. Parsere spænder fra enkle til komplekse og bruges til alt fra at se på kommandolinjemuligheder til fortolkning af Java-kildekode. I JavaWorldI december-udgaven viste jeg dig Jack, en automatisk parsergenerator, der konverterer grammatikspecifikationer på højt niveau til Java-klasser, der implementerer parseren beskrevet af disse specifikationer. Denne måned viser jeg dig de ressourcer, som Java leverer til at skrive målrettede leksikale analysatorer og parsere. Disse noget enklere parsere fylder hullet mellem enkel strengesammenligning og de komplekse grammatikker, som Jack kompilerer.
Formålet med leksikale analysatorer er at tage en strøm af inputtegn og afkode dem til højere tokens, som en parser kan forstå. Parsere forbruger output fra den leksikale analysator og fungerer ved at analysere rækkefølgen af returnerede tokens. Parseren matcher disse sekvenser til en sluttilstand, som kan være en af muligvis mange sluttilstande. Sluttilstandene definerer mål af parseren. Når en sluttilstand er nået, udfører programmet ved hjælp af parseren en eller anden handling - enten opsætning af datastrukturer eller udførelse af en handlingsspecifik kode. Derudover kan parsere opdage - fra rækkefølgen af tokens, der er blevet behandlet - når der ikke kan nås nogen juridisk sluttilstand; på det tidspunkt identificerer parseren den aktuelle tilstand som en fejltilstand. Det er op til applikationen at beslutte, hvilken handling der skal foretages, når parseren identificerer enten en sluttilstand eller en fejltilstand.
Standard Java-klassebasen inkluderer et par leksikale analyseklasser, men den definerer ikke nogen generelle parserklasser. I denne kolonne vil jeg se nærmere på de leksikale analysatorer, der følger med Java.
Java's leksikale analysatorer
Java Language Specification, version 1.0.2, definerer to leksikale analyseklasser, StringTokenizer og StreamTokenizer. Fra deres navne kan du udlede det StringTokenizer anvendelser Snor objekter som input, og StreamTokenizer anvendelser InputStream genstande.
StringTokenizer-klassen
Af de to tilgængelige leksikale analyseklasser er den nemmeste at forstå StringTokenizer. Når du konstruerer en ny StringTokenizer objekt, konstruktormetoden tager to værdier - en inputstreng og en afgrænsningsstreng. Klassen konstruerer derefter en række tokens, der repræsenterer tegnene mellem skilletegnene.
Som en leksikalsk analysator, StringTokenizer kunne formelt defineres som vist nedenfor.
[~ delim1, delim2, ..., delimN] :: Polet
Denne definition består af et regulært udtryk, der matcher alle tegn undtagen afgrænsningstegnene. Alle tilstødende matchende tegn samles i et enkelt token og returneres som et token.
Den mest almindelige anvendelse af StringTokenizer klasse er til at adskille et sæt parametre - såsom en komma-adskilt liste med tal. StringTokenizer er ideel i denne rolle, fordi den fjerner separatorerne og returnerer dataene. Det StringTokenizer klasse giver også en mekanisme til at identificere lister, hvor der er "null" tokens. Du bruger null-tokens i applikationer, hvor nogle parametre enten har standardværdier eller ikke kræves at være til stede i alle tilfælde.
Applet'en nedenfor er enkel StringTokenizer træner. Kilden til StringTokenizer-appleten er her. For at bruge appleten skal du skrive tekst, der skal analyseres, i inputstrengområdet og derefter skrive en streng bestående af skilletegn i området Separatorstreng. Til sidst skal du klikke på Tokenize! knap. Resultatet vises i tokenlisten under inputstrengen og organiseres som et token pr. Linje.
Overvej som et eksempel en streng, "a, b, d", sendt til a StringTokenizer objekt, der er konstrueret med et komma (,) som skilletegn. Hvis du lægger disse værdier i træningsapplet ovenfor, vil du se, at Tokenizer objekt returnerer strengene "a", "b" og "d." Hvis din hensigt var at bemærke, at en parameter manglede, er du muligvis overrasket over at se ingen indikation af dette i tokensekvensen. Evnen til at opdage manglende tokens er aktiveret af den booleske Return Separator, der kan indstilles, når du opretter en Tokenizer objekt. Med denne parameter indstillet, når Tokenizer er konstrueret, returneres hver separator også. Klik på afkrydsningsfeltet for Return Separator i appleten ovenfor, og lad strengen og separatoren være alene. Nu er det Tokenizer returnerer "a, komma, b, komma, komma og d." Ved at bemærke, at du får to skilletegn i rækkefølge, kan du bestemme, at et "null" -token var inkluderet i inputstrengen.
Tricket med succes at bruge StringTokenizer i en parser defineres input på en sådan måde, at afgrænsningstegnet ikke vises i dataene. Det er klart, at du kan undgå denne begrænsning ved at designe den i din applikation. Metodedefinitionen nedenfor kan bruges som en del af en applet, der accepterer en farve i form af røde, grønne og blå værdier i sin parameterstrøm.
/ ** * Parser en parameter i formularen "10,20,30" som en * RGB-tuple for en farveværdi. * / 1 Farve getColor (strengnavn) {2 strengdata; 3 StringTokenizer st; 4 int rød, grøn, blå; 5 6 data = getParameter (navn); 7 hvis (data == null) 8 returnerer null; 9 10 st = ny StringTokenizer (data, ","); 11 prøv {12 rød = Integer.parseInt (st.nextToken ()); 13 grøn = Integer.parseInt (st.nextToken ()); 14 blå = Integer.parseInt (st.nextToken ()); 15} fange (Undtagelse e) {16 returnere null; // (FEJLSTAT) kunne ikke analysere det 17} 18 returnere ny farve (rød, grøn, blå); // (SLUTTSTAT) udført. 19} Koden ovenfor implementerer en meget enkel parser, der læser strengen "nummer, nummer, nummer" og returnerer en ny Farve objekt. I linje 10 opretter koden en ny StringTokenizer objekt, der indeholder parameterdataene (antag, at denne metode er en del af en applet) og en skilletegnliste, der består af kommaer. I linje 12, 13 og 14 ekstraheres hvert token derefter fra strengen og konverteres til et tal ved hjælp af heltal parseInt metode. Disse konverteringer er omgivet af en prøv / fange blokere, hvis nummerstrengene ikke var gyldige tal eller Tokenizer kaster en undtagelse, fordi den er løbet tør for tokens. Hvis alle tallene konverteres, nås sluttilstanden og a Farve objekt returneres Ellers er fejltilstanden nået og nul returneres.
En funktion af StringTokenizer klasse er, at den let kan stables. Se på den navngivne metode getColor nedenfor, hvilket er linierne 10 til 18 i ovenstående metode.
/ ** * Parse en farvetuple "r, g, b" i en AWT Farve objekt. * / 1 Farve getColor (strengdata) {2 int rød, grøn, blå; 3 StringTokenizer st = ny StringTokenizer (data, ","); 4 prøv {5 rød = Integer.parseInt (st.nextToken ()); 6 grøn = Integer.parseInt (st.nextToken ()); 7 blå = Integer.parseInt (st.nextToken ()); 8} fange (Undtagelse e) {9 return null; // (FEJLSTAT) kunne ikke analysere det 10} 11 returnere ny farve (rød, grøn, blå); // (SLUTTSTAT) udført. 12} En lidt mere kompleks parser vises i nedenstående kode. Denne parser er implementeret i metoden getColors, som er defineret til at returnere en matrix af Farve genstande.
/ ** * Analyser et sæt farver "r1, g1, b1: r2, g2, b2: ...: rn, gn, bn" i * en række AWT-farveobjekter. * / 1 Farve [] getColors (String data) {2 Vector accum = new Vector (); 3 farve cl, resultat []; 4 StringTokenizer st = ny StringTokenizer (data, ":"); 5 mens (st.hasMoreTokens ()) {6 cl = getColor (st.nextToken ()); 7 hvis (cl! = Null) {8 accum.addElement (cl); 9} ellers {10 System.out.println ("Fejl - dårlig farve."); 11} 12} 13 hvis (akkum.størrelse () == 0) 14 returnerer null; 15 resultat = ny farve [akkum.størrelse ()]; 16 for (int i = 0; i <accum.size (); i ++) {17 result [i] = (Color) accum.elementAt (i); 18} 19 returresultat; 20} I ovenstående metode, som kun er lidt forskellig fra getColor metode opretter koden i linje 4 til 12 en ny Tokenizer for at udtrække tokens omgivet af kolon (:). Som du kan læse i dokumentationskommentaren til metoden, forventer denne metode, at farvetubletter adskilles med kolon. Hvert opkald til næsteToken i StringTokenizer klasse returnerer et nyt token, indtil strengen er opbrugt. De returnerede tokens er strengene med tal adskilt af kommaer; disse token strenge er fodret til getColor, som derefter udtrækker en farve fra de tre tal. Oprettelse af et nyt StringTokenizer objekt ved hjælp af et token returneret af en anden StringTokenizer objekt tillader, at parserkoden, vi har skrevet, er lidt mere sofistikeret om, hvordan den fortolker strengindgangen.
Så nyttigt som det er, vil du til sidst udtømme evnerne hos StringTokenizer klasse og er nødt til at gå videre til sin storebror StreamTokenizer.
StreamTokenizer-klassen
Som navnet på klassen antyder, a StreamTokenizer objekt forventer, at dets input kommer fra et InputStream klasse. Ligesom StringTokenizer ovenfor konverterer denne klasse inputstrømmen til klumper, som din parsingskode kan fortolke, men det er her ligheden slutter.
StreamTokenizer er en borddrevet leksikalsk analysator. Dette betyder, at alle mulige inputtegn tildeles en betydning, og scanneren bruger betydningen af det aktuelle tegn til at beslutte, hvad de skal gøre. I implementeringen af denne klasse tildeles tegn en af tre kategorier. Disse er:
Hvidt rum tegn - deres leksikale betydning er begrænset til at adskille ord
Ord tegn - de skal aggregeres, når de støder op til et andet ordtegn
- Almindelig tegn - de skal straks returneres til parseren
Forestil dig implementeringen af denne klasse som en simpel tilstandsmaskine, der har to tilstande - ledig og ophobe. I hver tilstand er inputet et tegn fra en af ovenstående kategorier. Klassen læser karakteren, kontrollerer dens kategori og foretager sig noget og går videre til den næste tilstand. Følgende tabel viser denne tilstandsmaskine.
| Stat | Indgang | Handling | Ny stat |
|---|---|---|---|
| ledig | ord Karakter | skub tilbage karakter | ophobe |
| almindelig Karakter | returnere karakter | ledig | |
| hvidt rum Karakter | forbruge karakter | ledig | |
| ophobe | ord Karakter | tilføj til det aktuelle ord | ophobe |
| almindelig Karakter | returner det aktuelle ord skub tilbage karakter | ledig | |
| hvidt rum Karakter | returner det aktuelle ord forbruge karakter | ledig |
Oven på denne enkle mekanisme StreamTokenizer klasse tilføjer flere heuristikker. Disse inkluderer nummerbehandling, citeret strengbehandling, kommentarbehandling og end-of-line-behandling.
Det første eksempel er nummerbehandling. Visse tegnsekvenser kan fortolkes som repræsenterende en numerisk værdi. For eksempel repræsenterer rækkefølgen af tegn 1, 0, 0,. Og 0 ved siden af hinanden i inputstrømmen den numeriske værdi 100.0. Når alle de cifrede tegn (0 til 9), punkttegnet (.) Og minus (-) tegnet er angivet som en del af ord Indstil StreamTokenizer klassen kan blive fortalt at fortolke det ord, det er ved at vende tilbage som et muligt tal. Indstilling af denne tilstand opnås ved at ringe til parseNumre metode på det tokenizer-objekt, som du instantierede (dette er standard). Hvis analysatoren er i akkumuleret tilstand, og det næste tegn ville ikke være en del af et tal, kontrolleres det aktuelt akkumulerede ord for at se, om det er et gyldigt tal. Hvis den er gyldig, returneres den, og scanneren flytter til den næste passende tilstand.
Det næste eksempel er citeret strengbehandling. Det er ofte ønskeligt at videregive en streng, der er omgivet af et anførselstegn (typisk dobbelt (") eller enkelt (') citat) som et enkelt token. StreamTokenizer klasse giver dig mulighed for at angive et hvilket som helst tegn som et citerende tegn. Som standard er det tegnene med enkelt citat (') og dobbelt citat ("). Tilstandsmaskinen er modificeret til at forbruge tegn i akkumuleringstilstand, indtil enten et andet citattegn eller et sluttegn behandles. For at give dig citerer citattegnet, behandler analysatoren citattegnet efterfulgt af et skråstreg (\) i inputstrømmen og inde i et citat som et ordtegn.