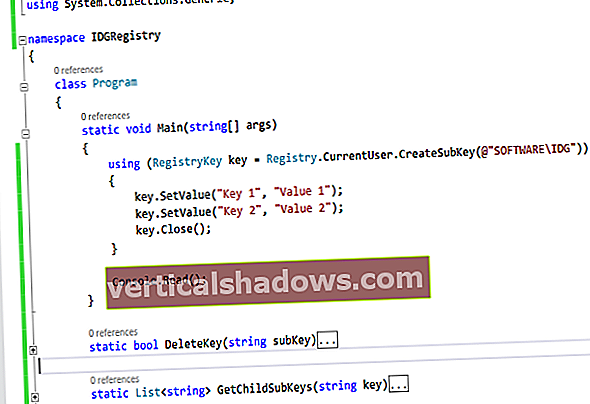
Pooling ressourcer (også kaldet pooling af objekter) blandt flere klienter er en teknik, der bruges til at fremme genbrug af objekter og til at reducere omkostningerne ved at skabe nye ressourcer, hvilket resulterer i bedre ydeevne og kapacitet. Forestil dig et kraftigt Java-serverprogram, der sender hundredvis af SQL-forespørgsler ved at åbne og lukke forbindelser for hver SQL-anmodning. Eller en webserver, der serverer hundredvis af HTTP-anmodninger, der håndterer hver anmodning ved at gyde en separat tråd. Eller forestil dig at oprette en XML-parserinstans for hver anmodning om at analysere et dokument uden at genbruge forekomsterne. Dette er nogle af de scenarier, der berettiger til optimering af de ressourcer, der bruges.
Ressourceforbrug kan til tider vise sig at være kritisk for tunge applikationer. Nogle berømte websteder er lukket ned på grund af deres manglende evne til at håndtere tunge belastninger. De fleste problemer i forbindelse med tunge belastninger kan håndteres på makroniveau ved hjælp af grupperings- og belastningsbalanceringsfunktioner. Bekymringer forbliver på applikationsniveau med hensyn til overdreven oprettelse af objekter og tilgængeligheden af begrænsede serverressourcer som hukommelse, CPU, tråde og databaseforbindelser, som kan repræsentere potentielle flaskehalse og, når de ikke udnyttes optimalt, nedbringer hele serveren.
I nogle situationer kan databasens brugspolitik håndhæve en grænse for antallet af samtidige forbindelser. En ekstern applikation kan også diktere eller begrænse antallet af samtidige åbne forbindelser. Et typisk eksempel er et domæneregister (som Verisign), der begrænser antallet af tilgængelige aktive sokkelforbindelser til registratorer (som BulkRegister). Samling af ressourcer har vist sig at være en af de bedste muligheder for at håndtere disse typer problemer og hjælper til en vis grad også med at opretholde de nødvendige serviceniveauer til virksomhedsapplikationer.
De fleste J2EE-applikationsserverleverandører leverer ressourcepooling som en integreret del af deres web- og EJB-containere (Enterprise JavaBean). For databaseforbindelser leverer serverleverandøren normalt en implementering af Datakilde interface, som fungerer sammen med JDBC (Java Database Connectivity) driverleverandører ConnectionPoolDataSource implementering. Det ConnectionPoolDataSource implementering fungerer som en ressource manager forbindelsesfabrik til pooled java.sql.Tilslutning genstande. Tilsvarende samles EJB-forekomster af statsløse sessionsbønner, meddelelsesdrevne bønner og enhedsbønner i EJB-containere for højere gennemstrømning og ydeevne. XML-parser-forekomster er også kandidater til pooling, fordi oprettelsen af parser-forekomster bruger meget af et systems ressourcer.
En vellykket implementering af open source ressource-pooling er Commons Pool framework's DBCP, en database-pooling-komponent fra Apace Software Foundation, der i vid udstrækning anvendes i virksomhedsklasser i produktionsklassen. I denne artikel diskuterer jeg kort internt i Commons Pool-rammen og bruger det derefter til at implementere en trådpulje.
Lad os først se på, hvad rammen giver.
Commons Pool rammer
Commons Pool-rammen tilbyder en grundlæggende og robust implementering til pooling af vilkårlige objekter. Der leveres flere implementeringer, men til denne artikels formål bruger vi den mest generiske implementering, the GenericObjectPool. Det bruger en CursorableLinkedList, som er en dobbeltkoblet listeimplementering (en del af Jakarta Commons Collections), som den underliggende datastruktur for at holde de objekter, der samles.
Ovenpå giver rammen et sæt grænseflader, der leverer livscyklusmetoder og hjælpermetoder til styring, overvågning og udvidelse af puljen.
Grænsefladen org.apache.commons.PoolableObjectFactory definerer følgende livscyklusmetoder, som viser sig at være vigtige for implementering af en pooling-komponent:
// Opretter en forekomst, der kan returneres af poolen public Object makeObject () {} // Ødelægger en forekomst, der ikke længere er nødvendig af poolen public void destroyObject (Object obj) {} // Valider objektet, før det bruges public boolean validateObject (Objektobjekt) {} // Initialiser en instans, der skal returneres af puljen, offentlig ugyldig aktivObject (Objektobjekt) {} // Geninitialiser en forekomst, der skal returneres til poolen, ugyldig passivateObject (Objektobjekt) {}Som du kan finde ud af ved hjælp af metodens signaturer, handler denne grænseflade primært om følgende:
makeObject (): Implementer objektoprettelsendestroyObject (): Implementere objektet ødelæggelsevalidateObject (): Valider objektet, før det brugesaktiverObjekt (): Implementere objektets initialiseringskodepassivateObject (): Implementere objektets uninitialiseringskode
En anden kerneinterface—org.apache.commons.ObjectPool—Definerer følgende metoder til styring og overvågning af puljen:
// Få en forekomst fra min pool Objekt lånObject () kaster Undtagelse; // Returner en instans til min pool ugyldige returnObject (Objekt obj) kaster Undtagelse; // Ugyldiggør et objekt fra puljen ugyldigt ugyldigtObject (Objekt obj) kaster Undtagelse; // Bruges til forudindlæsning af en pool med inaktive objekter ugyldigt addObject () kaster Undtagelse; // Returner antallet af inaktive forekomster int getNumIdle () kaster UnsupportedOperationException; // Returner antallet af aktive forekomster int getNumActive () kaster UnsupportedOperationException; // Rydder de inaktive objekter ugyldige clear () kaster Exception, UnsupportedOperationException; // Luk poolen ugyldig tæt () kaster Undtagelse; // Indstil ObjectFactory, der skal bruges til at oprette forekomster ugyldige setFactory (PoolableObjectFactory-fabrik) kaster IllegalStateException, UnsupportedOperationException;Det ObjectPool interface implementering tager en PoolableObjectFactory som et argument i dets konstruktører og derved delegere objektoprettelse til dets underklasser. Jeg taler ikke meget om designmønstre her, da det ikke er vores fokus. For læsere, der er interesserede i at se på UML-klassediagrammer, se Ressourcer.
Som nævnt ovenfor, klassen org.apache.commons.GenericObjectPool er kun en implementering af org.apache.commons.ObjectPool interface. Rammen giver også implementeringer til nøgleobjekter ved hjælp af grænsefladerne org.apache.commons.KeyedObjectPoolFactory og org.apache.commons.KeyedObjectPool, hvor man kan knytte en pool til en nøgle (som i HashMap) og administrere således flere puljer.
Nøglen til en vellykket pooling-strategi afhænger af, hvordan vi konfigurerer puljen. Dårligt konfigurerede puljer kan være ressourcehogs, hvis konfigurationsparametrene ikke er velindstillede. Lad os se på nogle vigtige parametre og deres formål.
Konfigurationsoplysninger
Puljen kan konfigureres ved hjælp af GenericObjectPool.Config klasse, som er en statisk indre klasse. Alternativt kunne vi bare bruge GenericObjectPoolsetter metoder til at indstille værdierne.
Følgende liste viser nogle af de tilgængelige konfigurationsparametre til GenericObjectPool implementering:
maxIdle: Det maksimale antal soveforekomster i poolen uden at frigive ekstra genstande.minIdle: Det mindste antal soveforekomster i poolen uden at der oprettes ekstra objekter.maxActive: Det maksimale antal aktive forekomster i puljen.timeBetweenEvictionRunsMillis: Antallet af millisekunder, der skal sove mellem kørsler af tomgangsobjektudskydningstråden. Når det er negativt, kører ingen tomgangsobjekt-evictor-tråd. Brug kun denne parameter, når du vil have evictor-tråden til at køre.minEvictableIdleTimeMillis: Den mindste tid, hvor et objekt, hvis det er aktivt, kan sidde inaktiv i puljen, før det er berettiget til udkastning af tomgangsobjektudsenderen. Hvis der angives en negativ værdi, udsendes ingen genstande på grund af inaktiv tid alene.testOnBorrow: Når "sandt" er objekter valideret. Hvis objektet mislykkes med validering, vil det blive droppet fra puljen, og puljen vil forsøge at låne en anden.
Optimale værdier skal angives for ovenstående parametre for at opnå maksimal ydelse og kapacitet. Da brugsmønsteret varierer fra applikation til applikation, skal du indstille puljen med forskellige kombinationer af parametre for at nå frem til den optimale løsning.
For at forstå mere om puljen og dens interne, lad os implementere en trådpulje.
Foreslåede krav til trådpuljer
Antag, at vi fik at vide at designe og implementere en trådpoolkomponent til en jobplanlægning for at udløse job ved bestemte tidsplaner og rapportere færdiggørelsen og muligvis resultatet af udførelsen. I et sådant scenario er formålet med vores trådpul at samle et forudsat antal tråde og udføre de planlagte job i uafhængige tråde. Kravene er opsummeret som følger:
- Tråden skal være i stand til at påkalde enhver vilkårlig klassemetode (det planlagte job)
- Tråden skal være i stand til at returnere resultatet af en udførelse
- Tråden skal kunne rapportere afslutningen af en opgave
Det første krav giver mulighed for en løst koblet implementering, da det ikke tvinger os til at implementere en interface som Kan køres. Det gør det også nemt at integrere. Vi kan implementere vores første krav ved at give tråden følgende oplysninger:
- Klassens navn
- Navnet på den metode, der skal påberåbes
- Parametrene, der skal overføres til metoden
- Parametertyperne for de parametre, der er sendt
Det andet krav gør det muligt for en klient, der bruger tråden, at modtage udførelsesresultatet. En simpel implementering ville være at gemme resultatet af udførelsen og give en tilgangsmetode som getResult ().
Det tredje krav er noget relateret til det andet krav. Rapportering af en opgaves afslutning kan også betyde, at klienten venter på at få resultatet af udførelsen. For at håndtere denne kapacitet kan vi tilbyde en eller anden form for tilbagekaldsmekanisme. Den enkleste tilbagekaldsmekanisme kan implementeres ved hjælp af java.lang.Objekt's vente() og underrette() semantik. Alternativt kunne vi bruge Observer mønster, men lad os nu holde tingene enkle. Du kan blive fristet til at bruge java.lang.Tråd klassens tilslutte() metode, men det fungerer ikke, da den samlede tråd aldrig fuldender dens løb() metode og kører så længe puljen har brug for det.
Nu hvor vi har vores krav klar og en grov idé om, hvordan vi implementerer trådpuljen, er det tid til at lave en rigtig kodning.
På dette tidspunkt ligner vores UML klassediagram over det foreslåede design figuren nedenfor.

Implementering af trådpuljen
Trådobjektet, vi skal samle, er faktisk en indpakning omkring trådobjektet. Lad os kalde indpakningen Arbejdertråd klasse, der udvider java.lang.Tråd klasse. Før vi kan begynde at kode Arbejdertråd, skal vi implementere rammekravene. Som vi så tidligere, skal vi implementere PoolableObjectFactory, der fungerer som en fabrik, for at skabe vores poolbare Arbejdertråds. Når fabrikken er klar, implementerer vi TrådPool ved at udvide GenericObjectPool. Derefter afslutter vi vores Arbejdertråd.
Implementering af PoolableObjectFactory-grænsefladen
Vi begynder med PoolableObjectFactory interface og prøv at implementere de nødvendige livscyklusmetoder til vores trådpulje. Vi skriver fabrikklassen ThreadObjectFactory som følger:
offentlig klasse ThreadObjectFactory implementerer PoolableObjectFactory {
public Object makeObject () {return new WorkerThread (); } public void destroyObject (Object obj) {if (obj instanceof WorkerThread) {WorkerThread rt = (WorkerThread) obj; rt.setStopped (true); // Gør den kørende tråd til at stoppe}} public boolean validateObject (Object obj) {if (obj instanceof WorkerThread) {WorkerThread rt = (WorkerThread) obj; if (rt.isRunning ()) {if (rt.getThreadGroup () == null) {returner false; } returner sandt }} returner sandt; } offentlig ugyldig aktiveringObject (Objekt obj) {log.debug ("aktiverObject ..."); }
offentlig ugyldig passivateObject (Objekt obj) {log.debug ("passivateObject ..." + obj); hvis (obj instans af WorkerThread) {WorkerThread wt = (WorkerThread) obj; wt.setResult (null); // Ryd op i resultatet af udførelsen}}}
Lad os gennemgå hver metode i detaljer:
Metode makeObject () skaber Arbejdertråd objekt. For hver anmodning kontrolleres puljen for at se, om et nyt objekt skal oprettes, eller et eksisterende objekt skal genbruges. For eksempel, hvis en bestemt anmodning er den første anmodning, og puljen er tom, vises ObjectPool implementeringsopkald makeObject () og tilføjer Arbejdertråd til poolen.
Metode destroyObject () fjerner Arbejdertråd objekt fra puljen ved at sætte et boolesk flag og derved stoppe den kørende tråd. Vi vil se på dette stykke igen senere, men bemærker, at vi nu tager kontrol over, hvordan vores objekter ødelægges.