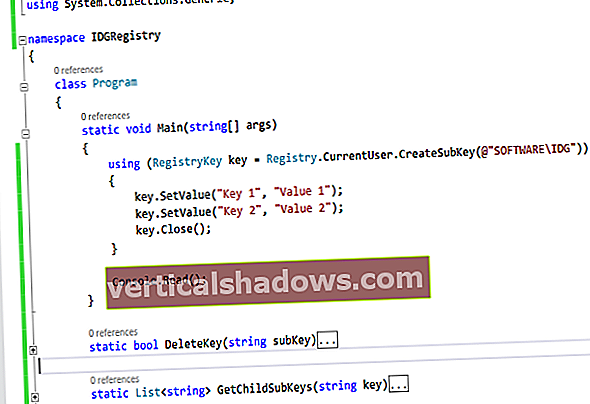
Tælling efter flere grupper - undertiden kaldet krydstabrapporter - kan være en nyttig måde at se på data lige fra opinionsundersøgelser til medicinske tests. For eksempel, hvordan stemte folk efter køn og aldersgruppe? Hvor mange softwareudviklere, der bruger både R og Python, er mænd mod kvinder?
Der er mange måder at gøre denne form for tælling efter kategorier i R. Her vil jeg gerne dele nogle af mine favoritter.
Til demoerne i denne artikel bruger jeg en delmængde af Stack Overflow Developers-undersøgelsen, som undersøger udviklere om snesevis af emner lige fra lønninger til anvendte teknologier. Jeg redigerer det med kolonner for sprog, køn, og hvis de koder som en hobby. Jeg tilføjede også min egen LanguageGroup-kolonne for, om en udvikler rapporterede ved hjælp af R, Python, begge eller ingen af dem.
Hvis du gerne vil følge med, har den sidste side i denne artikel instruktioner om, hvordan du downloader og vrider dataene for at få det samme datasæt, som jeg bruger.
Dataene har en række for hvert svar på undersøgelsen, og de fire kolonner er alle tegn.
str (mydata) 'data.frame': 83379 obs. af 4 variabler: $ Køn: chr "Man" "Man" "Man" "Man" ... $ LanguageWorkedWith: chr "HTML / CSS; Java; JavaScript; Python" "C ++; HTML / CSS; Python" "HTML / CSS "" C; C ++; C #; Python; SQL "... $ Hobbyist: chr" Ja "" Nej "" Ja "" Nej "... $ LanguageGroup: chr" Python "" Python "" Hverken "" Python "...
Jeg filtrerede rådataene for at gøre krydstaberne mere håndterbare, herunder fjerne manglende værdier og kun tage de to største køn, mand og kvinde.
Vogterpakken
Så hvad er kønsfordelingen inden for hver sproggruppe? Til denne type rapportering i en dataramme er en af mine go-to-værktøjer portrætterpakken tabyl () fungere.
Det basale tabyl () funktion returnerer en dataramme med optællinger. Det første kolonnenavn, du tilføjer til en tabyl () argument bliver række, og den anden den kolonne.
bibliotek (vagtmester) tabyl (mydata, Køn, LanguageGroup)Køn Begge hverken Python R Man 3264 43908 29044 969 Kvinde 374 3705 1940 175
Hvad er rart ved tabyl () er det også meget nemt at generere procent. Hvis du vil se procent for hver kolonne i stedet for rå totaler, skal du tilføje adorn_percentages ("col"). Du kan derefter pibe disse resultater i en formateringsfunktion som f.eksadorn_pct_formatting ().
tabyl (mydata, Køn, LanguageGroup)%>%adorn_percentages ("col")%>%
adorn_pct_formatting (cifre = 1)
Køn Begge hverken Python R Mand 89,7% 92,2% 93,7% 84,7% Kvinde 10,3% 7,8% 6,3% 15,3%
For at se procent efter række skal du tilføje adorn_percentages ("række").
Hvis du vil tilføje en tredje variabel, såsom Hobbyist, er det også nemt.
tabyl (mydata, Køn, LanguageGroup, Hobbyist)%>%adorn_percentages ("col")%>%
adorn_pct_formatting (cifre = 1)
Det bliver dog lidt sværere at visuelt sammenligne resultater på mere end to niveauer på denne måde. Denne kode returnerer a liste med en dataramme til hvert valg på tredje niveau:
$ Nej Køn Begge hverken Python R Man 79,6% 86,7% 86,4% 74,6% Kvinde 20,4% 13,3% 13,6% 25,4% $ Ja Køn Begge hverken Python R Man 91,6% 93,9% 95,0% 88,0% Kvinde 8,4% 6,1% 5,0% 12,0%
CGPfunktionspakken
CGPfunctions-pakken er værd at kigge efter nogle hurtige og nemme måder at visualisere krydstabsdata på. Installer det fra CRAN med det sædvanlige install.packages ("CGPfunktioner").
Pakken har to funktioner af interesse for undersøgelse af krydstabeller: PlotXTabs () og PlotXTabs2 (). Denne kode returnerer søjlediagrammer over dataene (første graf nedenfor):
bibliotek (CGPfunktioner)PlotXTabs (mydata)
 Screen shot af Sharon Machlis,
Screen shot af Sharon Machlis, PlotXTabs2 (mydata) opretter en graf med et andet udseende og nogle statistiske resuméer (anden graf til venstre).
Hvis du ikke har brug for eller ønsker disse oversigter, kan du fjerne dem med results.subtitle = FALSK, såsomPlotXTabs2 (mydata, LanguageGroup, Gender, results.subtitle = FALSE).
 Screen shot af Sharon Machlis,
Screen shot af Sharon Machlis, PlotXTabs2 () har et par dusin argumentmuligheder, herunder titel, billedtekst, forklaringer, farveskema og en af fire plottyper: side, stak, mosaik eller procent. Der er også indstillinger, som ggplot2-brugere kender, såsom ggtheme og palette. Du kan se flere detaljer i funktionens hjælpefil.
Vtree-pakken
Vtree-pakken genererer grafik til krydstabeller i modsætning til grafer. Kører hovedet vtree () funktion på en variabel, f.eks
bibliotek (vtree)vtree (mydata, "LanguageGroup")
giver dig dette grundlæggende svar:
 Sharon Machlis,
Sharon Machlis, Jeg er ikke interesseret i farveindstillingerne her, men du kan bytte i en RColorBrewer-palet. vtrees paletargument bruger palet numre, ikke navne; du kan se, hvordan de er nummereret i dokumentationen til vtree-pakken. Jeg kunne f.eks. Vælge 3 til grønne og 5 til lilla. Desværre giver disse standarder dig en mere intens farve til nederste tælle tal, hvilket ikke altid giver mening (og fungerer ikke godt for mig i dette eksempel). Jeg kan ændre den standardadfærd med sortfill = SAND at bruge den mere intense farve til højere værdi.
vtree (mydata, "LanguageGroup", palette = 3, sortfill = TRUE)
 Sharon Machlis,
Sharon Machlis, Hvis du finder den mørke farve gør det svært at læse tekst, er der nogle muligheder. En mulighed er at bruge almindeligt argument, såsomvtree (mydata, "LanguageGroup", plain = TRUE). En anden mulighed er at indstille en enkelt udfyldningsfarve i stedet for en palet ved hjælp af fyldfarve argument, såsomvtree (mydata, LanguageGroup ", fillcolor =" # 99d8c9 ").
For at se på to variabler i en krydstabrapport skal du blot tilføje et andet kolonnenavn og en palet eller farve, hvis du ikke vil have standard. Du kan bruge den almindelige mulighed eller angive to paletter eller to farver. Nedenfor valgte jeg bestemte farver i stedet for paletter, og jeg roterede også grafen for at læse lodret.
vtree (mydata, c ("LanguageGroup", "Køn"),fillcolor = c (LanguageGroup = "# e7d4e8", Køn = "# 99d8c9"),
Horiz = FALSE)
 Sharon Machlis,
Sharon Machlis, Du kan tilføje mere end to kategorier, selvom det bliver lidt sværere at læse og følge, når træet vokser. Hvis du kun er interesseret i nogle af filialerne kan du angive, hvilken der skal vises med holde argument. Nedenfor satte jeg mig vtree () for kun at vise personer, der bruger R uden Python, eller som bruger både R og Python.
vtree (mydata, c ("Køn", "LanguageGroup", "Hobbyist"),horizon = FALSE, fillcolor = c (LanguageGroup = "# e7d4e8",
Køn = "# 99d8c9", Hobbyist = "# 9ecae1"),
keep = list (LanguageGroup = c ("R", "Both")), showcount = FALSE)
Da træet bliver så travlt, tror jeg, det hjælper at have enten Optællingen eller procenten som node-etiketter, ikke begge. Så det sidste argument i koden ovenfor, showcount = FALSE, indstiller grafen til kun at vise procentdele og ikke tælle.
 Sharon Machlis,
Sharon Machlis, Flere tæller efter gruppemuligheder
Der er andre nyttige måder at gruppere og tælle i R, inklusive base R, dplyr og data.table. Base R harxtabs () fungerer specifikt til denne opgave. Bemærk nedenstående formelsyntaks: en tilde og derefter en variabel plus en anden variabel.
xtabs (~ LanguageGroup + Køn, data = mydata)Køn Sprog Gruppe Mand Kvinde Begge 3264374 Hverken 43908 3705 Python 29044 1940 R 969 175
dplyr's tælle() funktion kombinerer "gruppere efter" og "tælle rækker i hver gruppe" i en enkelt funktion.
bibliotek (dplyr)min_summary%
count (LanguageGroup, Gender, Hobbyist, sort = TRUE)
my_summary SprogGruppe Køn Hobbyist n 1 Hverken mand Ja 34419 2 Python-mand Ja 25093 3 Hverken mand Nej 9489 4 Python-mand Nej 3951 5 Begge mand Ja 2807 6 Ingen af kvinderne Ja 2250 7 Ingen af kvinderne Nej 1455 8 Python-kvinden Ja 1317 9 R Mand Ja 757 10 Python-kvinde Nej 623 11 Begge mænd Nej 457 12 Begge kvinder Ja 257 13 R Mand nej 212 14 Begge kvinder Nej 117 15 R Kvinde Ja 103 16 R Kvinde Nej 72
I de tre nedenstående kodelinjer indlæser jeg data.table-pakken, opretter en data.table fra mine data og bruger derefter den specielle .N data.table symbol, der står for antallet af rækker i en gruppe.
bibliotek (data.table)mydt <- setDT (mydata)
mydt [, .N, by =. (LanguageGroup, Gender, Hobbyist)]
Visualisering med ggplot2
Som med de fleste data er ggplot2 et godt valg til at visualisere opsummerede resultater. Den første ggplot-graf nedenfor viser LanguageGroup på X-aksen og antallet for hver på Y-aksen. Fyldfarve repræsenterer, om nogen siger, at de koder som en hobby. Og facet_wrap siger: Lav en separat graf for hver værdi i kolonnen Køn.
bibliotek (ggplot2)ggplot (my_summary, aes (LanguageGroup, n, fill = Hobbyist)) +
geom_bar (stat = "identitet") +
facet_wrap (facetter = vars (Køn))
 Sharon Machlis,
Sharon Machlis, Da der er relativt få kvinder i prøven, er det vanskeligt at sammenligne procenter på tværs af køn, når begge grafer bruger den samme Y-akse-skala. Jeg kan dog ændre det, så hver graf bruger en separat skala ved at tilføje argumentet skalaer = “fri_y” til facet_wrap () fungere:
ggplot (my_summary, aes (LanguageGroup, n, fill = Hobbyist)) +geom_bar (stat = "identitet") +
facet_wrap (facetter = vars (Køn), skalaer = "fri_y")
Nu er det lettere at sammenligne flere variabler efter køn.
For flere R-tip, gå til siden "Gør mere med R" på eller tjek YouTube-playlisten "Gør mere med R".
Se den næste side for information om, hvordan man downloader og kæmper data, der bruges i denne demo.