Jeff Carpenter er teknisk evangelist hos DataStax.
Der har for nylig været en masse hype om grafdatabaser. Mens grafdatabaser som DataStax Enterprise Graph (baseret på Titan DB), Neo4 og IBM Graph har eksisteret i flere år, indikerer nylige meddelelser om administrerede cloud-tjenester som AWS Neptune og Microsofts tilføjelse af grafkapacitet til Azure Cosmos DB, at grafdatabaser er kommet ind i mainstream. Med al denne interesse, hvordan finder du ud af, om en grafdatabase passer til din ansøgning?
Hvad er en grafdatabase?
Lad os definere nogle terminologier, inden vi går videre. Hvad er en grafdatabase? Tænk på det med hensyn til datamodellen. En grafdatamodel består af hjørner der repræsenterer enhederne i et domæne, og kanter der repræsenterer forholdet mellem disse enheder. Fordi både hjørner og kanter kan have yderligere navne-værdipar kaldet ejendomme, denne datamodel er formelt kendt som en ejendomsgraf. Nogle grafdatabaser kræver, at du definerer en skema til din graf — dvs. definerende etiketter eller navne på dine hjørner, kanter og egenskaber, inden du udfylder data - mens andre databaser giver dig mulighed for at fungere uden et fast skema.
Som du måske har bemærket, er der ikke nye oplysninger i grafdatamodellen, som vi ikke kunne registrere i en traditionel relationsdatamodel. Når alt kommer til alt er det nemt at beskrive forhold mellem tabeller ved hjælp af fremmednøgler, eller vi kan beskrive egenskaber ved et forhold med en sammenføjningstabel. Hovedforskellen mellem disse datamodeller er den måde, data er organiseret på og få adgang til. Anerkendelsen af kanter som en "førsteklasses borger" ved siden af hjørner i grafdatamodellen gør det muligt for den underliggende databasemotor at gentage meget hurtigt i enhver retning gennem netværk af hjørner og kanter for at tilfredsstille applikationsforespørgsler, en proces kendt som gennemkørsel.
Fleksibiliteten i grafdatamodellen er en nøglefaktor, der driver den seneste stigning i populariteten af grafdatabaser. De samme krav til tilgængelighed og massiv skala, der styrede udviklingen og vedtagelsen af forskellige NoSQL-tilbud i løbet af de sidste 10 år, fortsætter med at bære frugt i den nylige graftrend.
Sådan ved du, hvornår du har brug for en grafdatabase
Som med enhver populær teknologi kan der imidlertid være en tendens til at anvende grafdatabaser på ethvert problem. Det er vigtigt at sikre dig, at du har en brugssag, der passer godt. For eksempel anvendes grafer ofte til problemdomæner som:
- Sociale netværk
- Anbefaling og personalisering
- Kunde 360, inklusive enhedsopløsning (korrelering af brugerdata fra flere kilder)
- Bedrageri
- Aktivforvaltning
Uanset om din brugssag passer inden for et af disse domæner eller ej, er der nogle andre faktorer, som du bør overveje, der kan hjælpe med at afgøre, om en grafdatabase passer til dig:
- Mange-til-mange relationer. I sin bog "Designing Data Intensive Applications" (O'Reilly) foreslår Martin Kleppmann, at hyppige mange-til-mange-forhold i dit problemdomæne er en god indikator for grafbrug, da relationsdatabaser har tendens til at kæmpe for at navigere effektivt i disse forhold.
- Høj værdi af forhold. En anden heuristik, jeg ofte har hørt: hvis forholdet mellem dine dataelementer er lige så vigtige eller vigtigere end selve elementerne, bør du overveje at bruge graf.
- Lav ventetid i stor skala. Tilføjelse af en anden database i din applikation tilføjer også kompleksitet til din applikation. Grafdatabasernes evne til at navigere gennem de forhold, der er repræsenteret i store datasæt hurtigere end andre typer databaser, er det, der berettiger denne ekstra kompleksitet. Dette gælder især i tilfælde, hvor en kompleks relationel sammenføjningsforespørgsel ikke længere udfører, og der ikke er nogen yderligere optimeringsgevinster, der skal opnås til forespørgslen eller relationsstrukturen.
Definition af grafskema og forespørgsler med Gremlin
Lad os se på, hvordan du kommer i gang ved hjælp af en grafdatabase ved hjælp af et rigtigt eksempel, det anbefalingssystem, som vi for nylig tilføjede til KillrVideo. KillrVideo er en referenceapplikation til deling og visning af videoer, som vi har bygget for at hjælpe udviklere med at lære, hvordan man bruger DataStax Enterprise, inklusive DataStax Enterprise Graph, en grafdatabase, der er bygget oven på meget skalerbare datateknologier, herunder Apache Cassandra og Apache Spark.
Det sprog, der bruges til at beskrive og interagere med grafer i DataStax Enterprise Graph, er Gremlin, som er en del af Apache TinkerPop-projektet. Gremlin er kendt som go-to-sproget til beskrivelse af grafgennemgange på grund af dets fleksibilitet, udvidelse og understøttelse af både deklarative og tvingende forespørgsler. Gremlin er baseret på Groovy-sproget, og drivere er tilgængelige på flere sprog. Vigtigst er det, at Gremlin understøttes af de mest populære grafdatabaser, herunder DataStax Enterprise Graph, Neo4j, AWS Neptune og Azure Cosmos DB.
Vi har designet en anbefalingsalgoritme til at identificere de data, vi har brug for som input. Fremgangsmåden var at generere anbefalinger til en given bruger baseret på videoer, som lignende brugere kunne lide. Vores mål var at generere anbefalinger i realtid, da brugere interagerer med KillrVideo-applikationen, dvs. som en OLTP-interaktion.
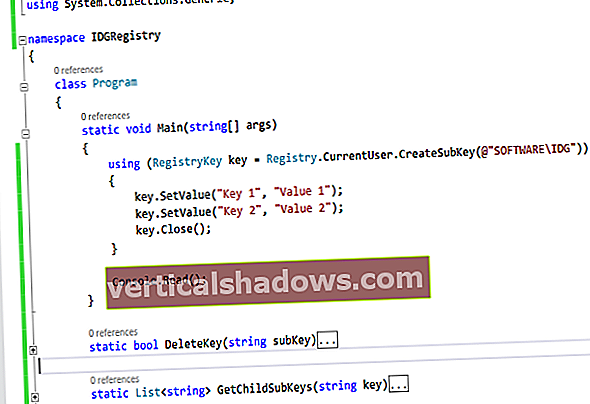
For at definere skemaet identificerede vi et undersæt af de data, der administreres af KillrVideo, som vi havde brug for til vores graf. Dette omfattede brugere, videoer, ratings og tags samt egenskaber for disse emner, som vi muligvis henviser til i algoritmen eller præsenterer i anbefalingsresultater. Vi oprettede derefter et grafskema i Gremlin, der så sådan ud:
// oprette toppunktetiketterschema.vertexLabel (“bruger”). partitionKey (‘userId’).
egenskaber ("userId", "email", "added_date"). ifNotExists (). create ();
schema.vertexLabel (“video”). partitionKey (‘videoId’).
egenskaber ("videoId", "navn", "beskrivelse", "tilføjet_dato",
preview_image_location ”). ifNotExists (). create ();
schema.vertexLabel (“tag”). partitionKey (‘name’).
egenskaber ("navn", "tagged_date"). ifNotExists (). create ();
// Opret kantetiketter
schema.edgeLabel ("rated"). multiple (). egenskaber ("rating").
forbindelse ("bruger", "video"). ifNotExists (). Opret ();
schema.edgeLabel ("uploadet"). single (). egenskaber ("added_date").
forbindelse ("bruger", "video"). ifNotExists (). Opret ();
schema.edgeLabel (“taggedWith”). enkelt ().
forbindelse ("video", "tag"). ifNotExists (). create ();
Vi valgte at modellere brugere, videoer og tags som hjørner og brugte kanter til at identificere, hvilke brugere der uploadede hvilke videoer, brugerbedømmelser af videoer og de tags, der var knyttet til hver video. Vi tildelte egenskaber til hjørner og kanter, der er henvist til i forespørgsler eller inkluderet i resultaterne. Det resulterende skema ser sådan ud i DataStax Studio, et notebook-udviklerværktøj til udvikling og udførelse af forespørgsler i CQL og Gremlin.
Baseret på dette skema definerede vi forespørgsler, der udfylder data i grafen, og forespørgsler, der henter data fra grafen. Lad os se på en grafforespørgsel, der genererer anbefalinger. Her er det grundlæggende flow: For en given bruger skal du identificere lignende brugere, der kunne lide videoer, som den givne bruger kunne lide, vælge videoer, som de lignende brugere også kunne lide, ekskludere videoer, som den givne bruger allerede har set, ordne disse videoer efter popularitet og give resultaterne.
def numRatingsToSample = 1000def localUserRatingsToSample = 10
def minPositiveRating = 4
def brugerID = ...
g.V (). har (“user”, “userId”, userID) .as (“^ currentUser”)
// få alle de videoer, som brugeren har set, og gem dem
.map (ud ('bedømt'). dedup (). fold ()). som ("^ WatchVideos")
// gå tilbage til den aktuelle bruger
.select (“^ currentUser”)
// identificer de videoer, som brugeren vurderede højt
.outE ('rated'). har ('rating', gte (minPositiveRating)). inV ()
// hvilke andre brugere vurderede disse videoer højt?
.inE ('rated'). har ('rating', gte (minPositiveRating))
// begrænse antallet af resultater, så dette fungerer som en OLTP-forespørgsel
.sample (numRatingsToSample)
// sorter efter vurdering for at favorisere brugere, der bedømte disse videoer højest
.by ('rating'). outV ()
// eliminere den nuværende bruger
.where (neq (“^ currentUser”))
Lad os pause et øjeblik for at få vejret. Indtil videre i denne gennemgang har vi identificeret lignende brugere. Den anden del af traversalen tager disse lignende brugere, griber et begrænset antal videoer, som de lignende brugere kunne lide, fjerner videoer, som brugeren allerede har set, og genererer et resultatsæt sorteret efter popularitet.
// vælg et begrænset antal højt vurderede videoer fra hver lignende bruger.local (outE ('rated'). har ('rating', gte (minPositiveRating)). limit (localUserRatingsToSample)). sæk (tildel). af ('rating'). inV ()
// ekskluder videoer, som brugeren allerede har set
.not (hvor (indenfor (“^ WatchVideos”)))
// identificer de mest populære videoer efter summen af alle ratings
.gruppe (). af (). af (sæk (). sum ())
// nu hvor vi har et stort kort over [video: score], skal du bestille det
.ordre (lokal) .by (værdier, dekr.) .begrænsning (lokal, 100) .vælg (nøgler) .udfold ()
// output anbefalede videoer inklusive den bruger, der uploadede hver video
.project ('video', 'bruger')
.ved()
.by (__. in (‘uploadet))
Mens denne gennemgang ser kompliceret ud, skal du huske, at det er hele forretningslogikken for en anbefalingsalgoritme. Vi vil ikke grave nærmere ind på hvert trin i denne gennemgang her, men sprogreferencen er en stor ressource, og der findes uddannelseskurser af høj kvalitet.
Jeg anbefaler at udvikle traversaler interaktivt over et repræsentativt datasæt ved hjælp af et værktøj som DataStax Studio eller Gremlin-konsollen fra Apache TinkerPop. Dette giver dig mulighed for hurtigt at gentage og forfine dine gennemgange. DataStax Studio er et webbaseret miljø, der giver flere måder at visualisere gennemkørselsresultater som netværk af noder og kanter, som vist på billedet nedenfor. Andre understøttede visninger inkluderer tabeller, diagrammer og grafer samt sporing af ydeevne.
 DataStax
DataStaxIntegrering af en grafdatabase i din arkitektur
Når du har designet dit grafskema og dine forespørgsler, er det tid til at integrere grafen i din applikation. Sådan integrerede vi DataStax Enterprise Graph i KillrVideo. KillrVideos multi-tier-arkitektur består af en webapplikation, der sidder oven på et sæt mikrotjenester, der administrerer brugere, videoer (inklusive tags) og ratings. Disse tjenester udnytter DataStax Enterprise Graph-databasen (bygget på Apache Cassandra) til datalagring og adgang til dataene ved hjælp af CQL.
Vi implementerede vores anbefalingsmotor som en del af tjenesten Forslag til videoer, som vist nedenfor. Denne tjeneste genererer en liste med anbefalinger givet et bruger-id. For at implementere anbefalingsmotoren oversatte vi Gremlin-gennemgangen beskrevet ovenfor til Java-kode.
 DataStax
DataStaxDenne arkitektur fremhæver en hyppig udfordring inden for mikroservicearkitekturer - behovet for at interagere med data, der ejes af flere tjenester. Som vist ovenfor er grafen, der bruges til at generere anbefalinger, afhængig af data fra tjenesterne User Management, Video Catalog og Ratings.
Vi bevarede dataejerskabet af vores eksisterende tjenester ved hjælp af asynkron besked. Tjenesterne User Management, Video Catalog og Ratings offentliggør begivenheder om dataændringer. Den foreslåede videotjeneste abonnerer på disse begivenheder og foretager tilsvarende opdateringer til grafen. De kompromiser, vi har lavet her, er typiske for applikationer, der bruger en multimodel tilgang, et emne, jeg udforskede i min tidligere artikel.
Implementering af Gremlin-traversaler i Java
DataStax Java Driver giver en venlig, flydende API til implementering af Gremlin-traversaler med DataStax Enterprise Graph. API'en gjorde det trivielt at migrere Groovy-baserede forespørgsler, vi oprettede i DataStax Studio, til Java-kode.
Vi var derefter i stand til at gøre vores Java-kode endnu mere læsbar og vedligeholdelig ved hjælp af en Gremlin-funktion kendt som DSL'er, domænespecifikke sprog. En DSL er en udvidelse af Gremlin til et bestemt domæne. Til KillrVideo oprettede vi en DSL til at udvide implementeringen af Gremlin traversal med vilkår, der er relevante for videodomænet. Det KillrVideoTraversalDsl klasse definerer forespørgselshandlinger såsom user (), som lokaliserer toppunktet i grafen med et angivet UUID, og recommendByUserRating (), der genererer anbefalinger til en leveret bruger baseret på parametre såsom en minimumsklassificering og et anmodet antal anbefalinger.
Brug af en DSL forenklet implementeringen af tjenesten Foreslåede videoer til noget som eksemplet nedenfor, hvilket skaber en GraphStatement som vi derefter udfører ved hjælp af DataStax Java Driver:
GraphStatement gStatement = DseGraph.statementFromTraversal (killr.users (userIdString).recommendByUserRating (100, 4, 500, 10)
);
Brug af en DSL tillod os at skjule noget af kompleksiteten af vores grafinteraktioner i genanvendelige funktioner, som derefter kan kombineres efter behov for at danne mere komplekse traversaler. Dette giver os mulighed for at implementere yderligere anbefalingsmotorer, der starter fra et valgt brugerpunkt, der leveres af bruger() metode og lade applikationen skifte mellem de forskellige implementeringer.
Et fungerende grafeksempel
Du kan se resultaterne af vores integration af DataStax Enterprise Graph i KillrVideo i afsnittet "Anbefalet til dig" i webapplikationen vist nedenfor. Prøv det selv på //www.killrvideo.com ved at oprette en konto og bedømme et par videoer.
 DataStax
DataStaxJeg håber, at denne artikel giver dig nogle gode ideer til, hvordan en grafdatabase kan give mening for din applikation, og hvordan du kommer i gang med Gremlin og DataStax Enterprise Graph.
Jeff Carpenter er teknisk evangelist hos DataStax, hvor han udnytter sin baggrund inden for systemarkitektur, mikroservices og Apache Cassandra for at hjælpe udviklere og driftsingeniører med at opbygge distribuerede systemer, der er skalerbare, pålidelige og sikre. Jeff er forfatteren af Cassandra: The Definitive Guide, 2. udgave.
—
New Tech Forum giver et sted at udforske og diskutere nye virksomhedsteknologier i hidtil uset dybde og bredde. Valget er subjektivt baseret på vores valg af de teknologier, som vi mener er vigtige og af største interesse for læserne. accepterer ikke markedsføringssikkerhed til offentliggørelse og forbeholder sig retten til at redigere alt bidraget indhold. Send alle henvendelser til[email protected].